Worked Example
Table of Contents
Intro
Prepping the Data
Filtering the Data
Extracting Data
Visualizing the Data
Getting the Status of the Data
Organzing the Data
Intro
This worked example does not cover basic twarc setup and configuration. If you have not installed twarc, do so at the twarc DocNow or on the updated twarc documentation page has been moved.
You are encouraged, but not required, to try out these utilities on your own before viewing the worked example code and outputs. Visit the Utilities Home page and the corresponding sections for an explanation of each utility, as well as parameters available that are not included in this worked example.
For the worked example, we will run through the 2019 Nipsey Hussle Funeral Tweets. The tweet ids are available under Downloadable Options on the right-hand side of the page and are named nipsey-ids.txt.gz. (Note: The extension .gz is a file format and software application used for file compression and decompression. If you don’t know how to open this type of file or are having trouble doing so, visit Resources).
Prepping the Data
The first step will be to unzip our dataset. It should unzip to a txt file titled ids.txt. For organizational purposes, we will rename this file nh_ids.txt for Nispey Hussle. You can keep the name ids.txt or modify it to fit your needs. See Resources for help on unzipping the txt.gz file.
There are 11,642,103 ids listed in nh_ids.txt. This amount of data is normally great for analysis because it gives us so much to work with. However, it also takes a long time to process. For this example, we will only be looking at the first 20,000 tweets. For ease of use, I have written the python program subset.py to do this. Look at the code documentation for more explanation of what it does and how it works. We will title our ouputted file nh_sub_ids.txt.
Alternatively, see the python program random_subset.py to create a subset of random tweet ids.
Next we will need to rehydrate the dataset.
twarc hydrate nh_sub_ids.txt > nh_sub_tweets.jsonl
Note: If an account or tweet has been deleted from Twitter, it cannot be rehydrated.
Filtering the Data
Filtering the data can be seen as a way to clean the data before analysis.
deduplicate.py
We’d like to start out by removing duplicate ids and retweets from our dataset.
python utils/deduplicate.py nh_sub_tweets.jsonl > nh_sub_deduplicate.jsonl
We can also run
python utils/deduplicate.py --extract-retweets nh_sub_tweets.jsonl > nh_sub_dedupretweets.jsonl
to extract just the retweets to a new JSON.
filter_date.py
Then we want to look at tweets made the day of Nipsey Hussle death (March 31st, 2019). This might not limit the date to only March 31st, 2019 with a bigger dataset (or when using random_subset.py) because you can only specify a min or a max date. If you would like to limit the date, you will have to run filter_date.py twice: the first time filtering by mindate OR maxdate, and the second time filtering the ouputted dataset by the remaining parameter. For our current dataset, this works because the tweets only date up to March 31st so by specifying a mindate, we are only left with tweets made on March 31st, 2019.
python utils/filter_date.py --mindate 31-march-2019 nh_sub_deduplicate.jsonl > nh_dod.jsonl
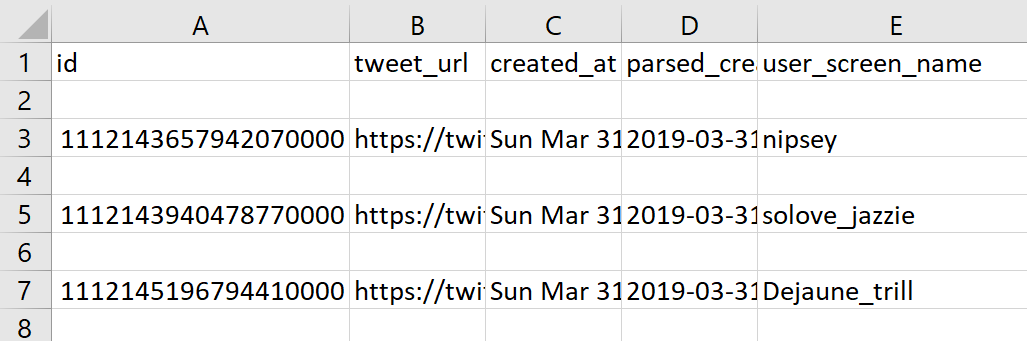
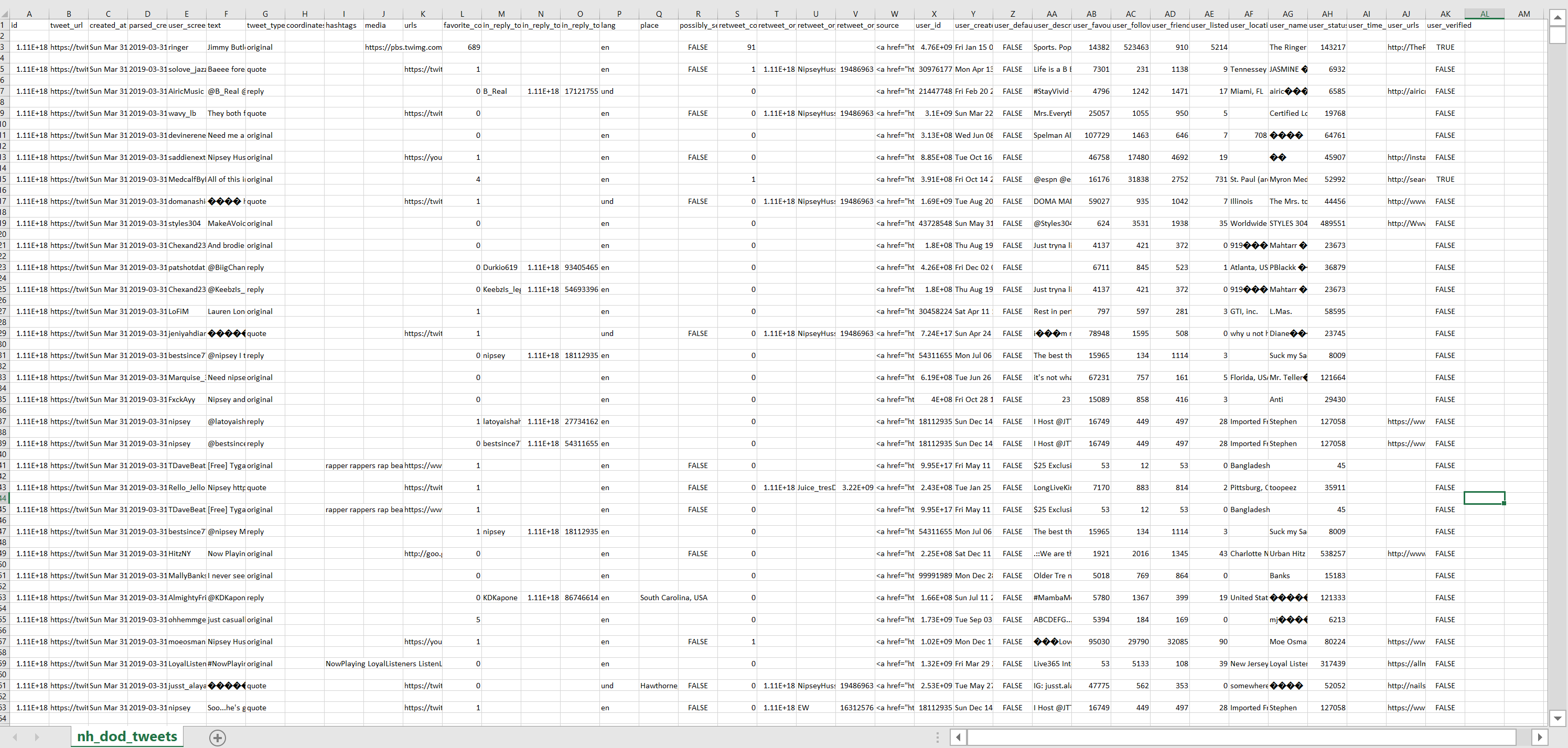
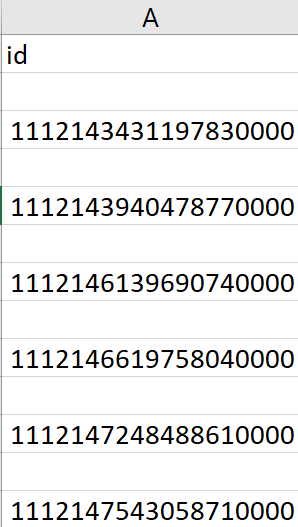
As we can see from the photo of the CSV (We can use the json2csv.py utility listed on the Visualization page and demonstrated below to check this utility and those following), the first tweet entries are from the DOD in order of time created.
filter_users.py
This one can be a little tricky if the input file doesn’t have proper formatting. The input must be supplied as a list in a TXT or CSV file. It can contain:
; screen names
; user ids
; screen name,user id
; user id,screen name
each on a separate line.
We’re going to use screen names for this example. We can collect these using json2csv.py.

We can then copy the screen names (in this case, the first screen names listed) into our file of choice.
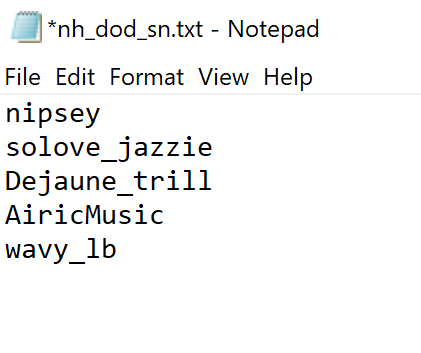
Once we run our usage command, we will get a JSON containing only the tweets made by the screen names we listed in the file.
python utils/filter_users.py nh_dod_sn.txt nh_dod.jsonl > nh_dod_users.jsonl

The output is the metadata about the users we supplied. Notice that there is no cap on the number of tweets by the same screen name.
geo.py
Before working with this utility, check out the not_mapping_twitter repo to read the precautions of geocoordinates.
Now we can create a file of tweets containing geo coordinates.
python utils/geo.py nh_dod.jsonl > nh_dod_geo.jsonl
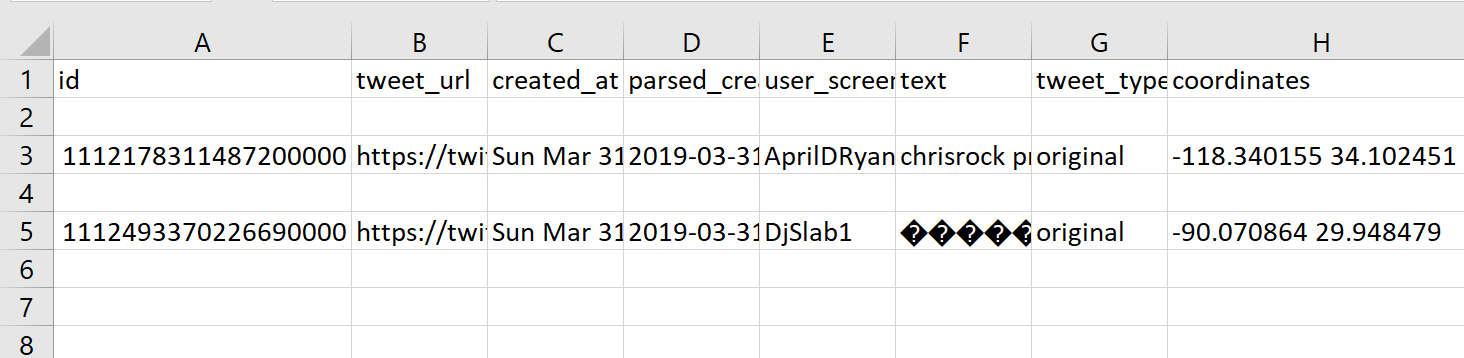
Based on our results, there are only two tweets in our sample dataset (after being filtered by DOD) that contain geo coordinates.
geofilter.py
geofilter.py works similarly to geo.py, but allows us to specify whether we want to filter by absence OR presence of geo coordinates. By specifying that we want to filter by tweets without geo coordinates, we can get the tweets not returned by geo.py.
python utils/geofilter.py nh_dod.jsonl --no-coordinates > nh_dod_geofilter.jsonl
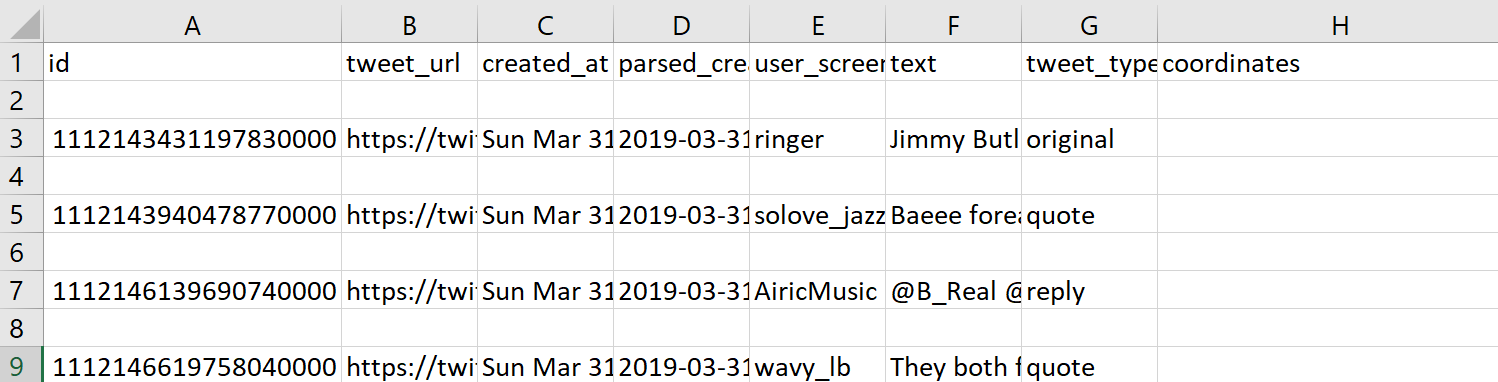
noretweets.py
Next, we’ll remove retweets from our dataset.
python utils/noretweets.py nh_dod.jsonl > nh_dod_noretweets.jsonl
sensitive.py
This utility will allow us to filter by the presence or absense of sensitive content in tweets.
python utils/sensitive.py nh_dod.jsonl > nh_dod_sensitive.jsonl
Column R is the variable possibly_sensitive, a boolean value (TRUE or FALSE) representing whether the tweet is considered sensitive. This first image is the dataset before running the utility sensitive.py.

The tweet that had been identified as sensitive has now been removed.
search.py
This utility enables us to search for specific keywords in the dataset. Tweets containing the keyword will be output to the output file. We’ll search the dataset for tweets containing the word ‘shot’.
python utils/search.py shot nh_dod.jsonl > nh_dod_search.jsonl
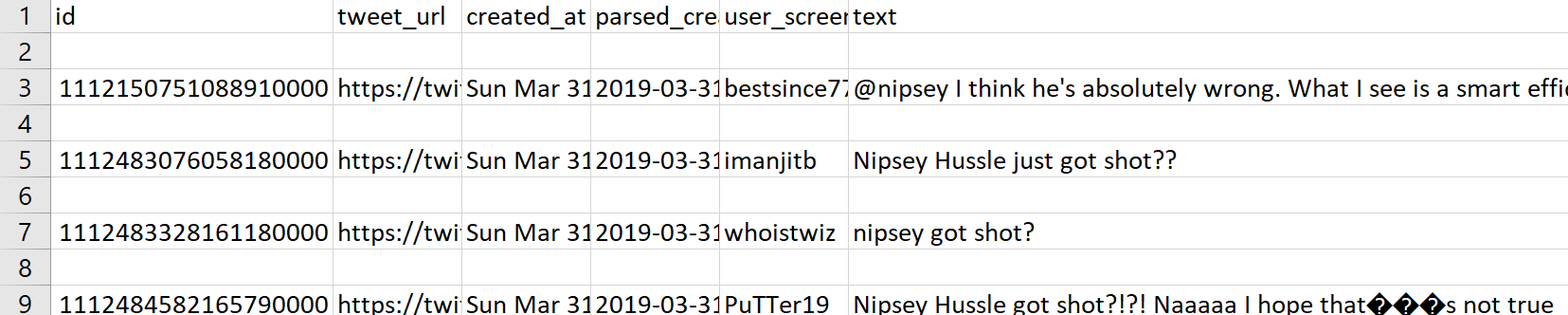
By searching shot, we can identify (for the most part) the tweets that are reacting to Nipsey Hussle getting shot. As you might notice, the first tweet returned is using ‘shot’ in a different context.
Extracting the Data
Data extraction utilities focus on extracting and returning specific tweet metadata.
embeds.py
This utility creates a list of media urls used in the dataset.
python utils/embeds.py nh_dod.jsonl > nh_dod_embeds.txt

emojis.py
We want to look at the emoji statistics i.e. which emojis are used and how often.
python utils/emojis.py nh_dod.jsonl > nh_dod_emojis.txt

As we can see, there are 5 emojis that are the same symbol of different skin tones. The general sentiment of all emojis listed are representative of religion, grief, and sadness.
extractor.py
python utils/extractor.py user:screen_name entities:hashtags -output nh_dod_extractor.csv
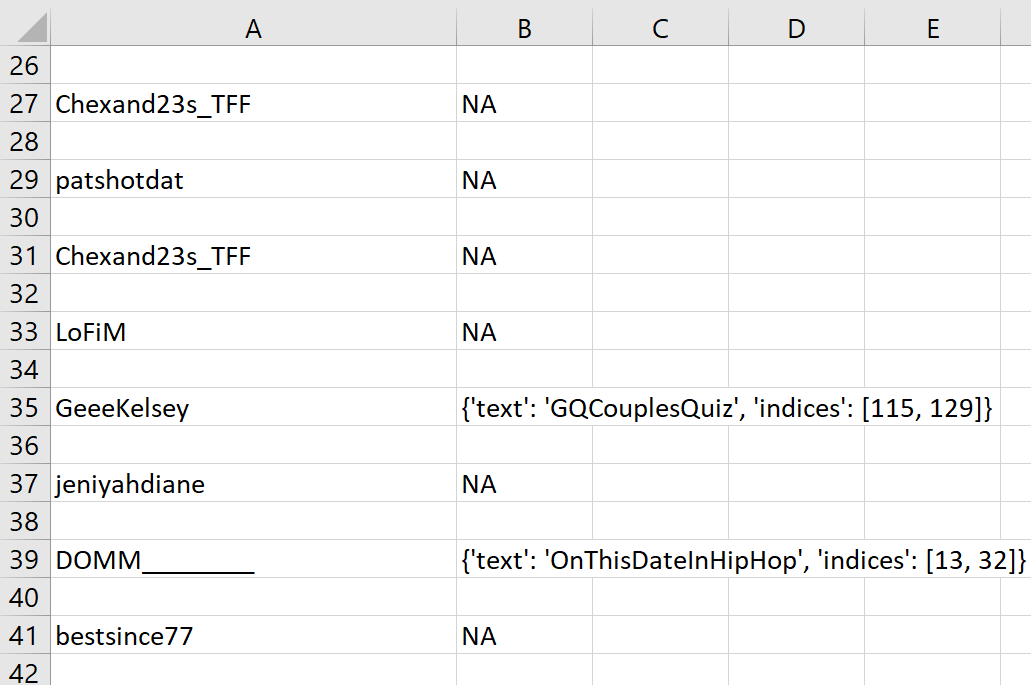
flakey.py
twarc dehydrate nh_dod.jsonl > nh_dod_ids.txt
python utils/flakey.py nh_dod_ids.txt > nh_dod_flakey.csv
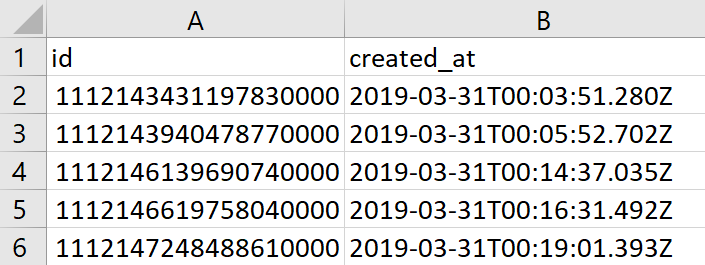
The output could also be a TXT.
media_urls.py
python utils/media_urls.py nh_dod.jsonl > nh_dod_media_urls.txt
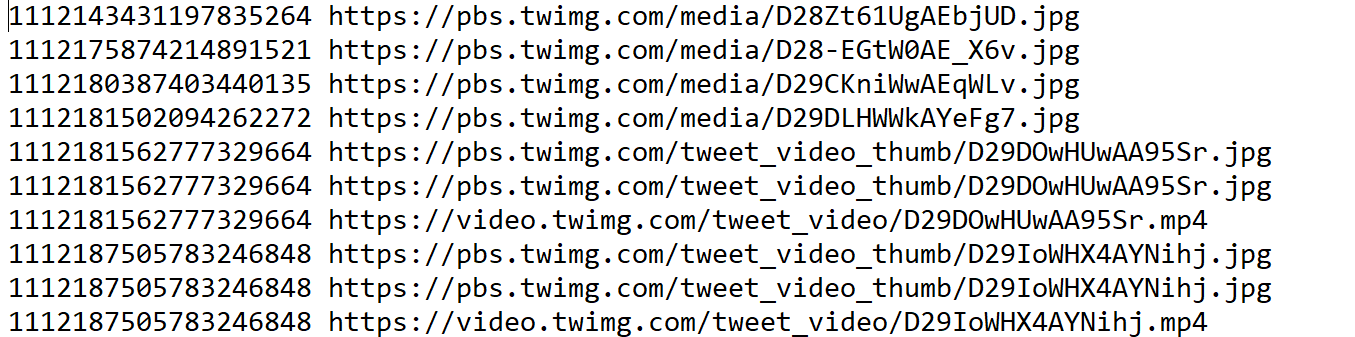
retweets.py
python utils/retweets.py nh_dod.jsonl > nh_dod_retweets.jsonl
This returns a blank JSON because there are no retweets in the subsetted dataset filtered by date. However, when we run this on the original subsetted dataset:
python utils/retweets.py nh_dod_tweets.jsonl > nh_dod_retweets.jsonl

tags.py
python utils/tags.py nh_dod.jsonl > nh_dod_hashtags.txt

times.py
python utils/times.py nh_dod.jsonl > nh_dod_times.txt
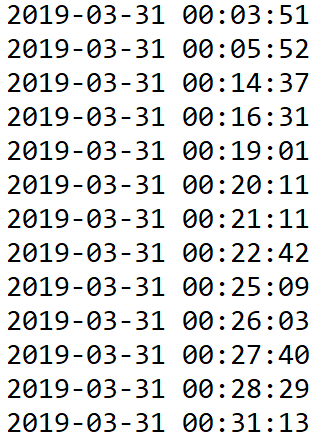
tweets.py
python utils/tweets.py nh_dod.jsonl > nh_dod_tweets.txt

Needs updated ability to handle tweets that have text labeled as “full_text” rather than “text”.
tweetometer.py
python utils/tweetometer.py nh_dod.jsonl > nh_dod_tweetometer.csv
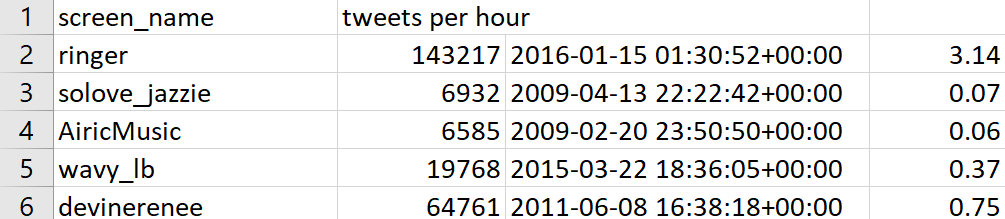
tweet_text.py
python utils/tweet_text.py nh_dod.jsonl > nh_dod_tweet_text.txt

tweet_urls.py
python utils/tweet_urls.py nh_dod.jsonl > nh_dod_tweet_urls.txt

users.py
python utils/users.py nh_dod.jsonl > nh_dod_users.txt

Visualizing the Data
This section allows us to create visuals of the data.
geojson.py
We can use geojson.py to create a GeoJSON file when the geospatial location of a tweet is available.
python utils/geojson.py nh_dod.jsonl > nh_dod.geojson
We can then use a GeoSpatial JSON reader to visualize this file on the map.
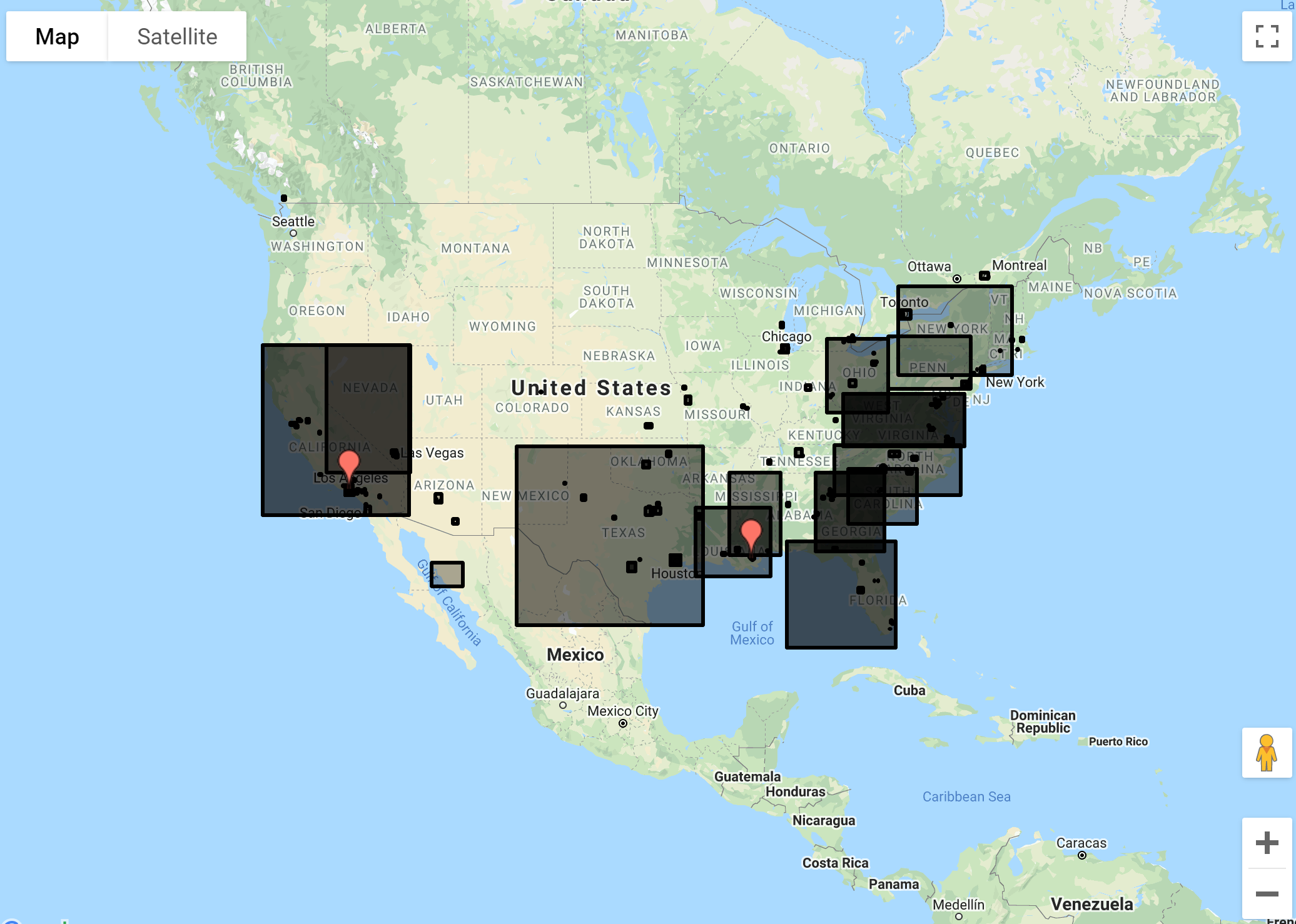
We can do further manipulation by creating a centroid instead of a bounding box.
python utils/geojson.py --centroid nh_dod.jsonl > nh_dod_centroid.geojson
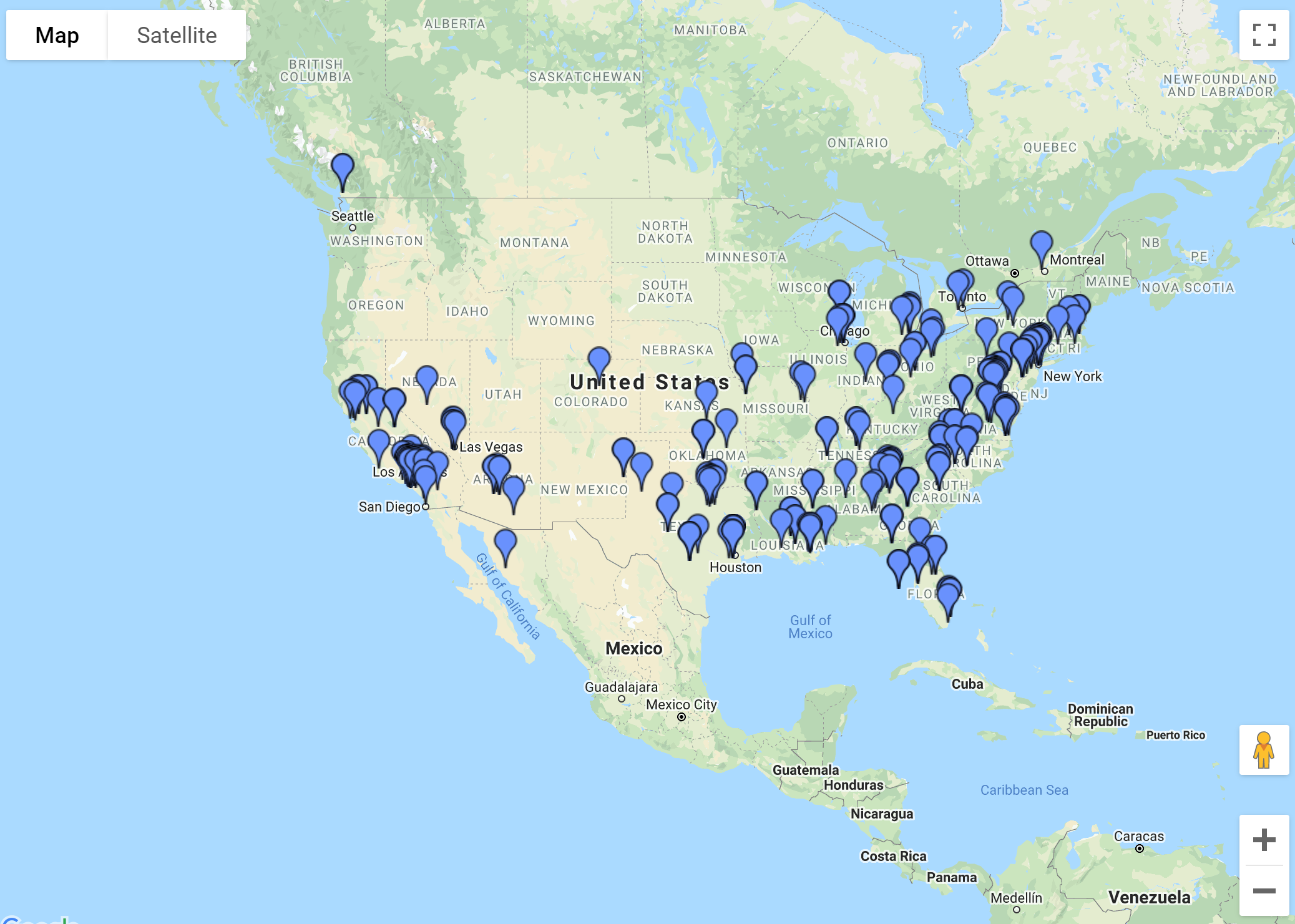
Or we can add a random lon and lat shift to the bounding box centroids (0-0.1)
python utils/geojson.py --centroid --fuzz 0.01 nh_dod.jsonl > nh_dod_fuzz.geojson
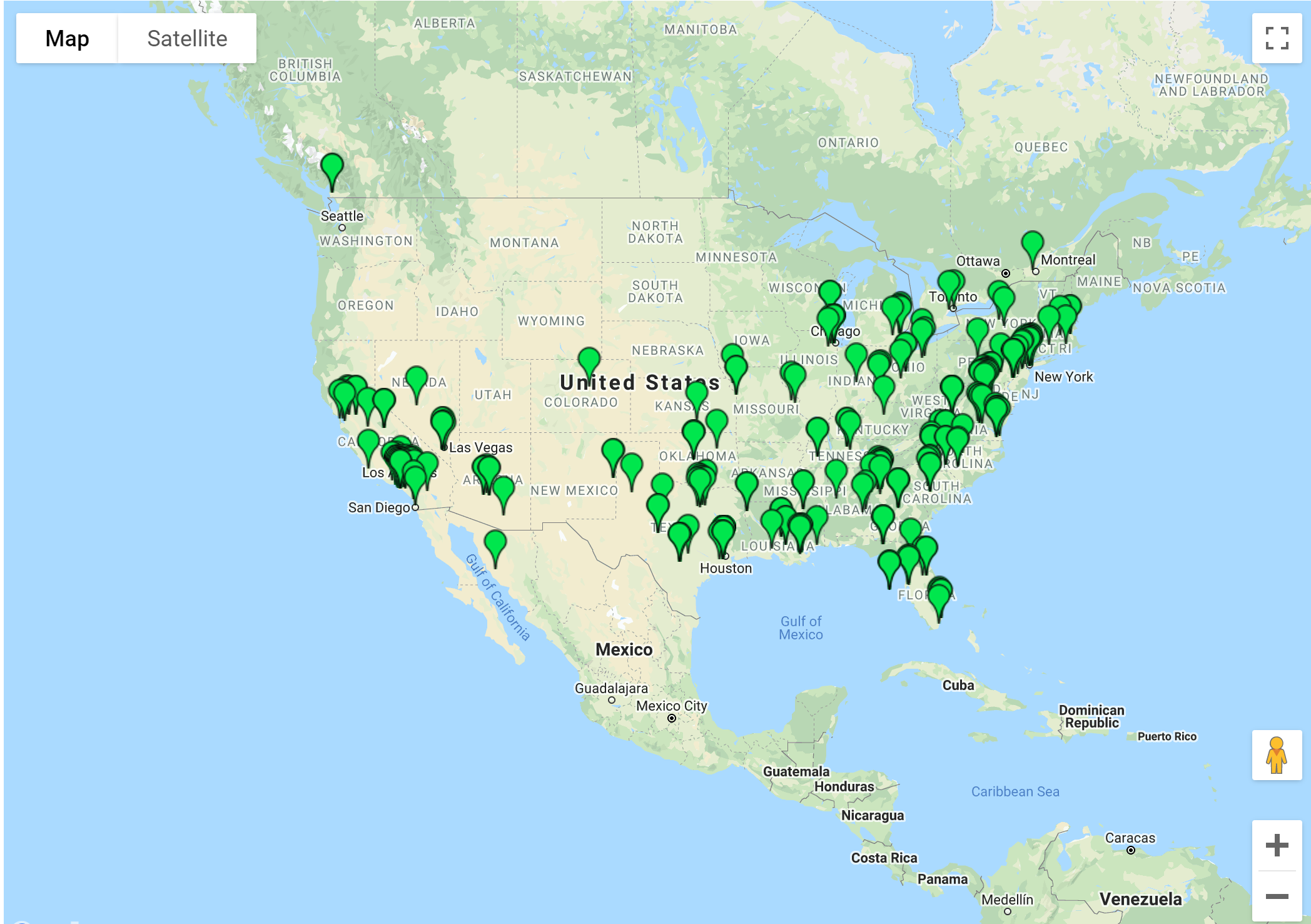
As we can see below, the shift is not too big.
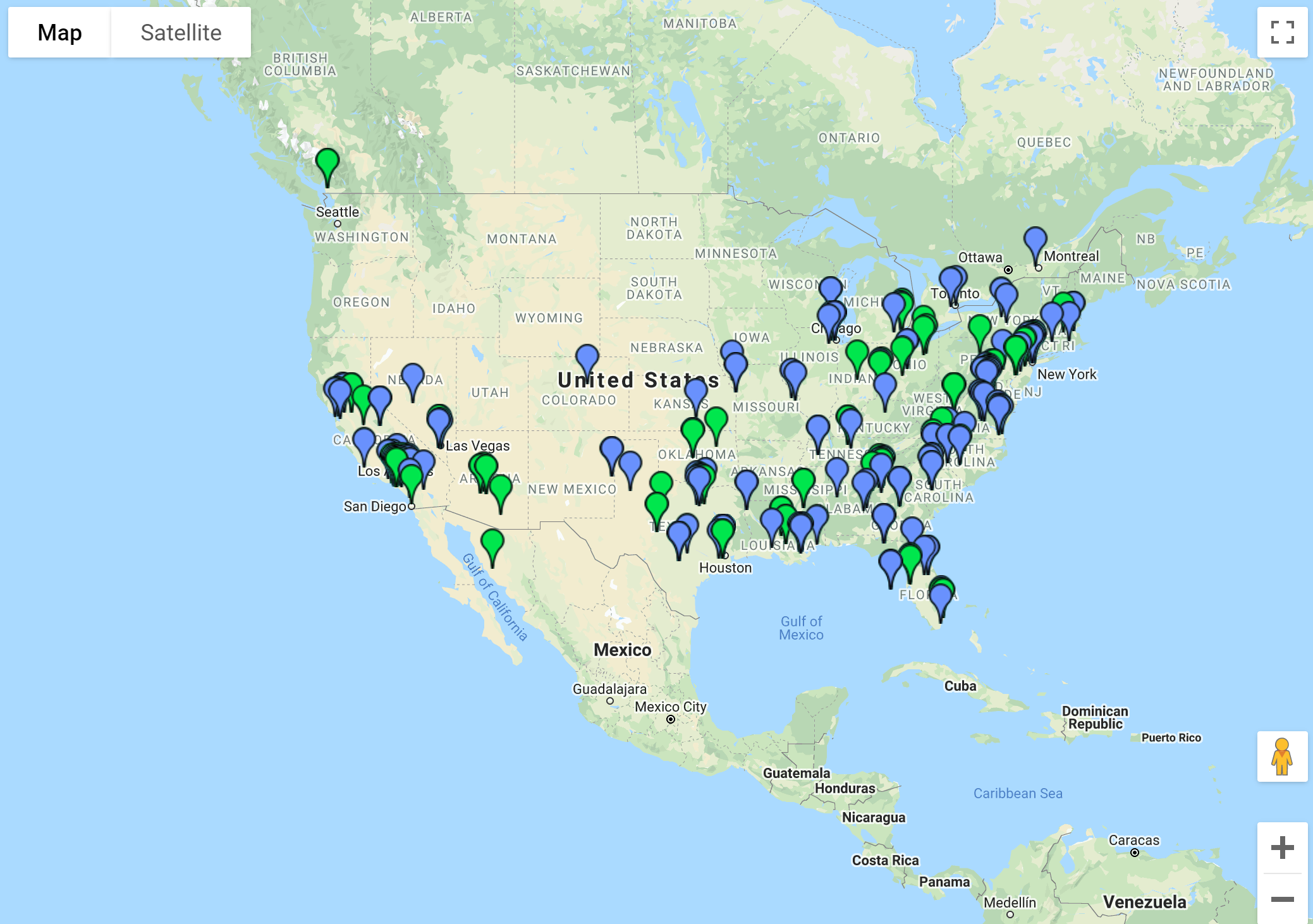
Jon’s tidbit about mapping Twitter
json2csv.py
We can view the tweets in a more cohesive manner by turning our json into a csv.
Note: if you’re using Windows and you get a charmap error, you can change your Region settings using the instructions here
python utils/json2csv.py nh_dod.jsonl > nh_dod_tweets.csv
network.py
python utils/network.py nh_dod.jsonl nh_dod_network.html
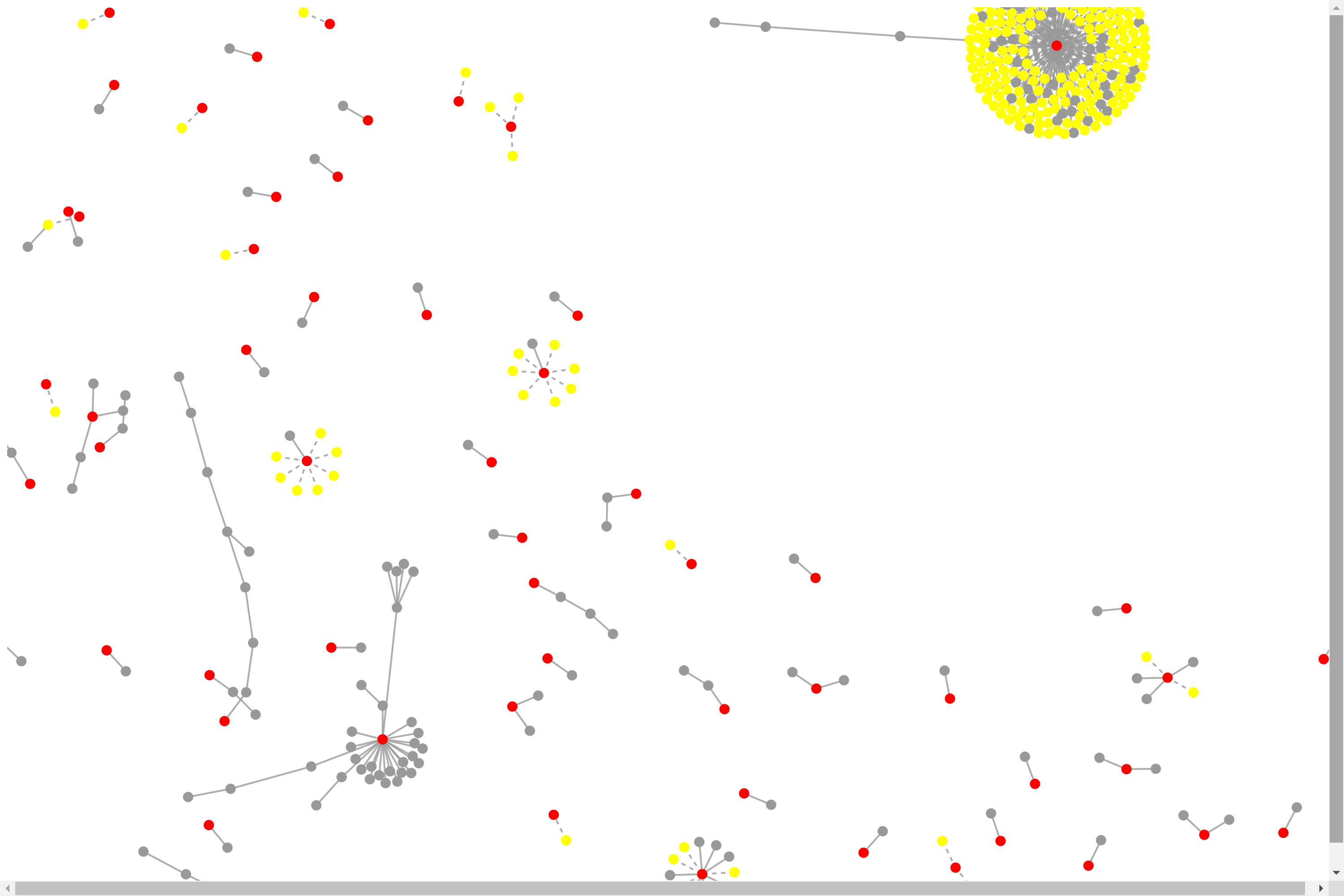
We can click on the dots to see the individual tweets. The central node(red) is the original tweet of a video interview. The connected nodes(yellow) are the replies and retweets to/of that video. The other nodes(gray) are attached by similarity to that central node and it’s surrounding nodes.
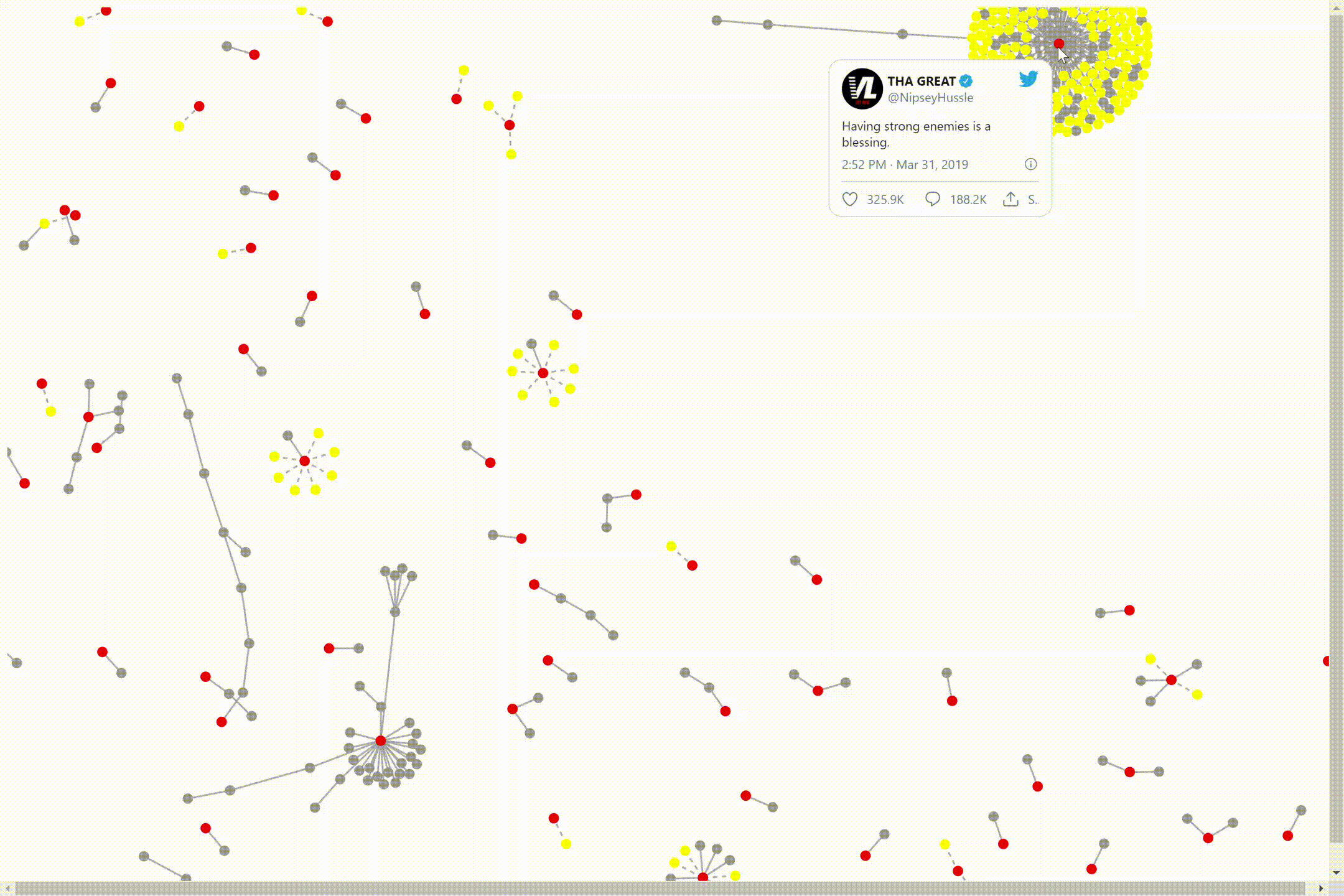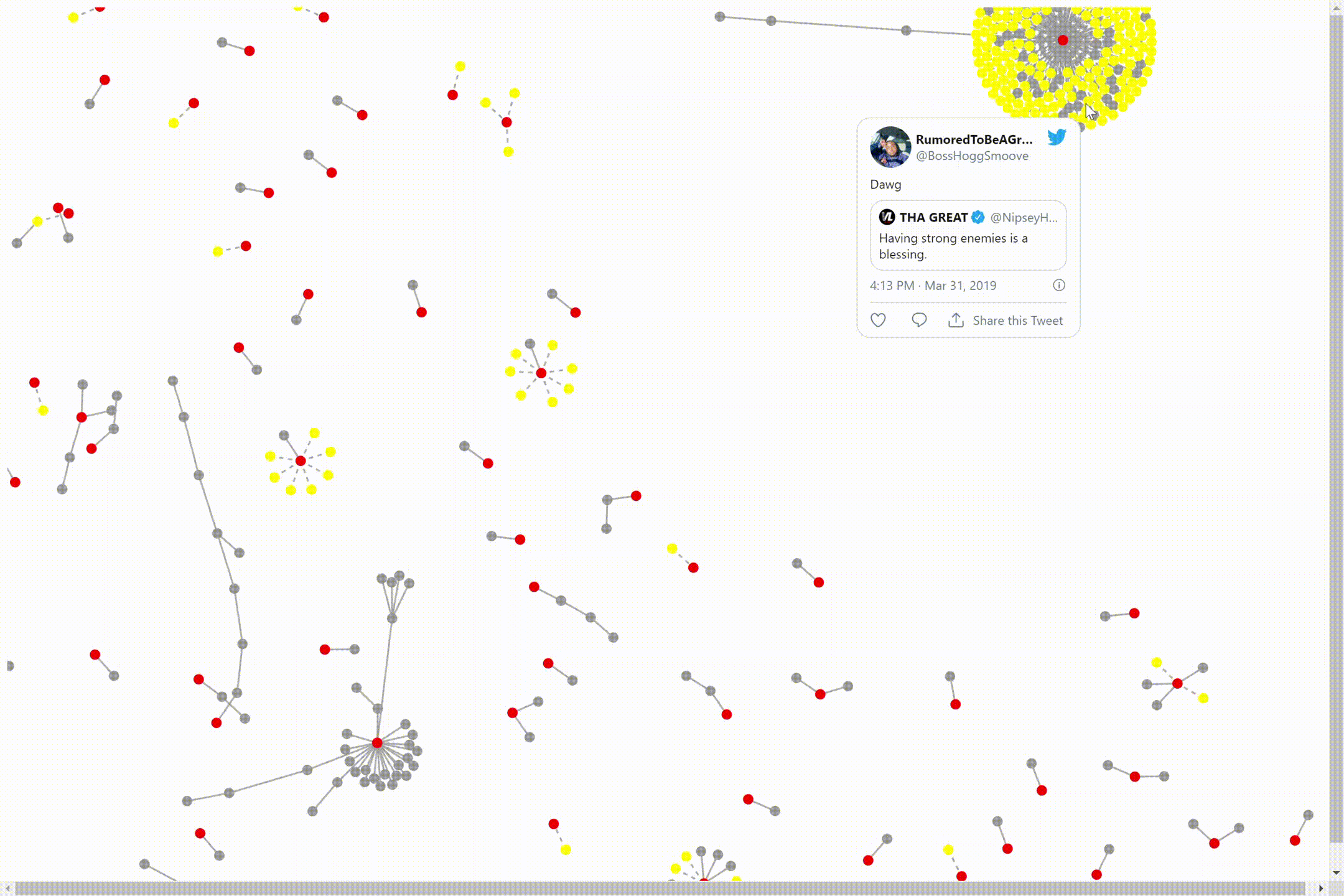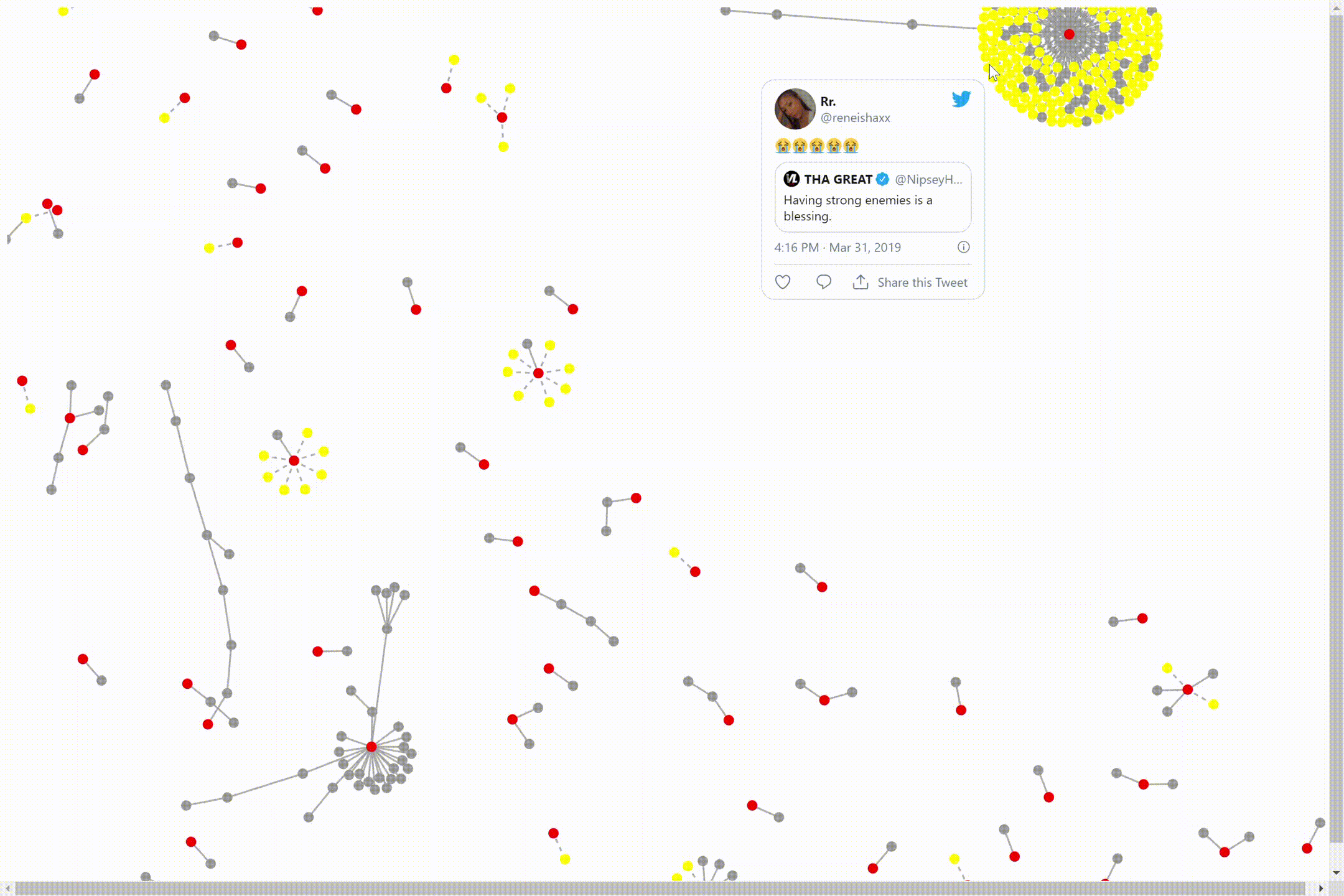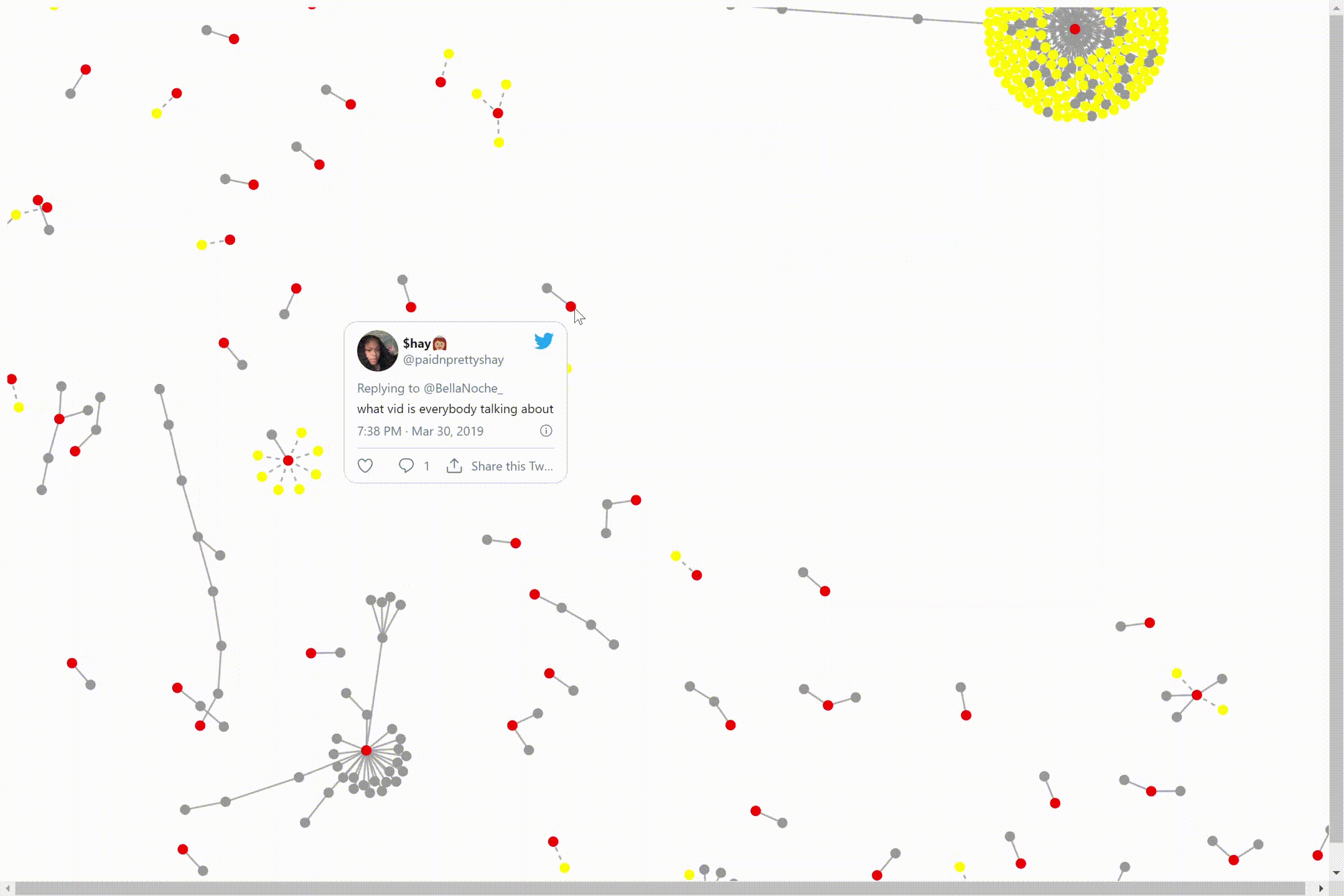
We can move the cluster by clicking on one of the nodes and dragging it to the place on our screen we would like it to be. The bigger the data size, the longer it will take to mode the nodes around. There are also nodes not attached to the cluster.
source.py
We can create a page with the sources(ranked most to least) used with source.py.
python utils/source.py nh_dod.jsonl > nh_dod_source.html
Note: The html is hardcoded in the source.py file. The title of the page is set to ‘Title Here’. To change this, you have to edit the html code itself from ‘Title Here’ to the title of your choice

We can click on the links provided for each source to learn more about them.
wall.py
We can also create a wall of tweets.
python utils/wall.py nh_dod.jsonl > nh_dod_wall.html
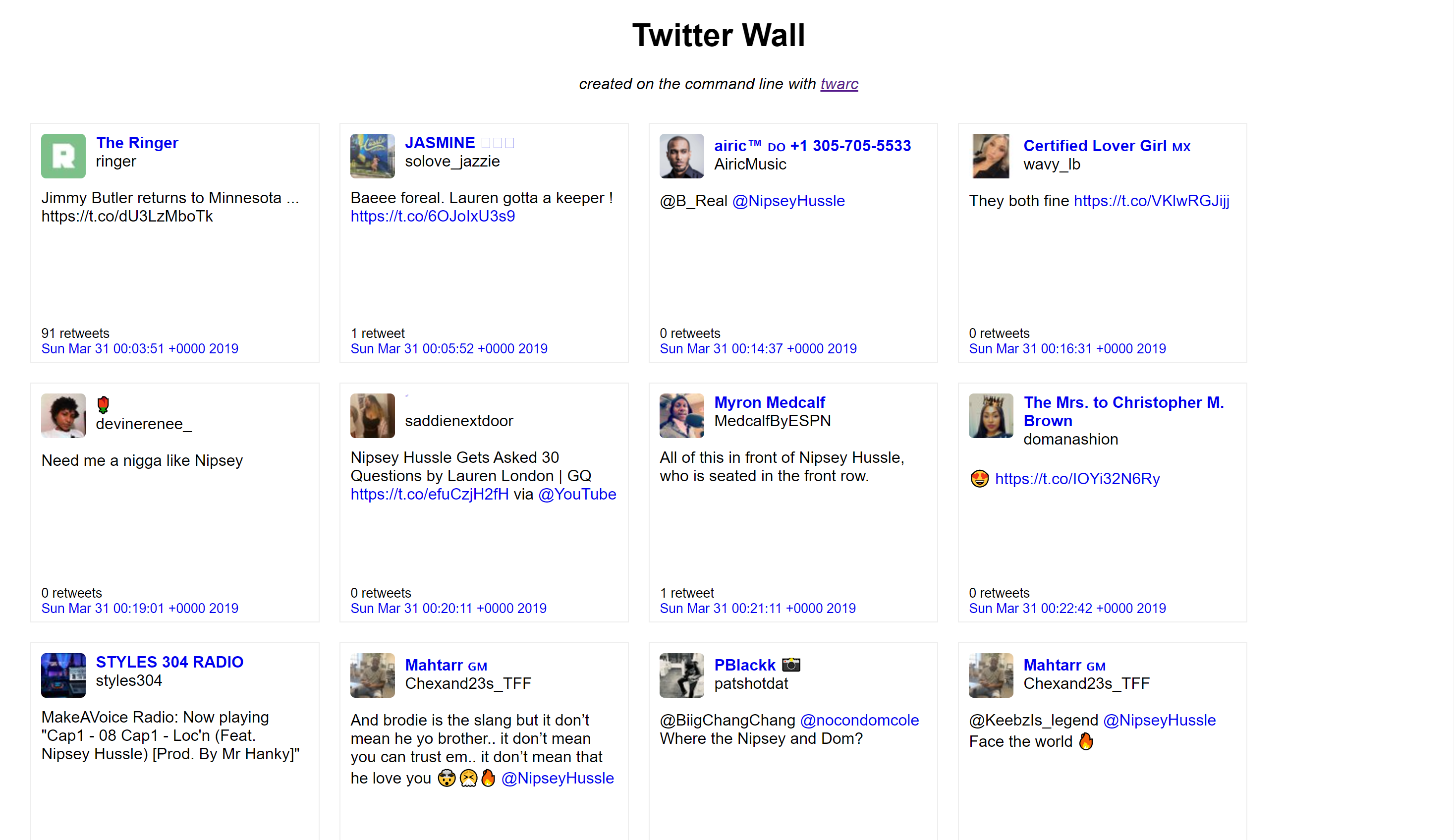
wordcloud.py
The last visualization tool we’ll go over is creating a wordcloud.
python utils/wordcloud.py nh_dod.jsonl > nh_dod_wordcloud.html

Getting the Status the Data
_deleted_users.py
We can run deleted_users.py to produce a JSON containing the tweets that have been deleted.
python utils/deleted_users.py nh_dod.jsonl > nh_dod_deleted_users.jsonl

deletes.py
We can then feed the output JSON into deletes.py to see the reason the tweet has been deleted.
python utils/deletes.py nh_dod_deleted_users.jsonl > nh_dod_deletes.txt

foaf.py
python utils/foaf.py 2267720350
%Just trying to figure out how to open the SQL file%
oembeds.py
python utils/oembeds.py nh_dod.jsonl > nh_dod_oembeds.jsonl
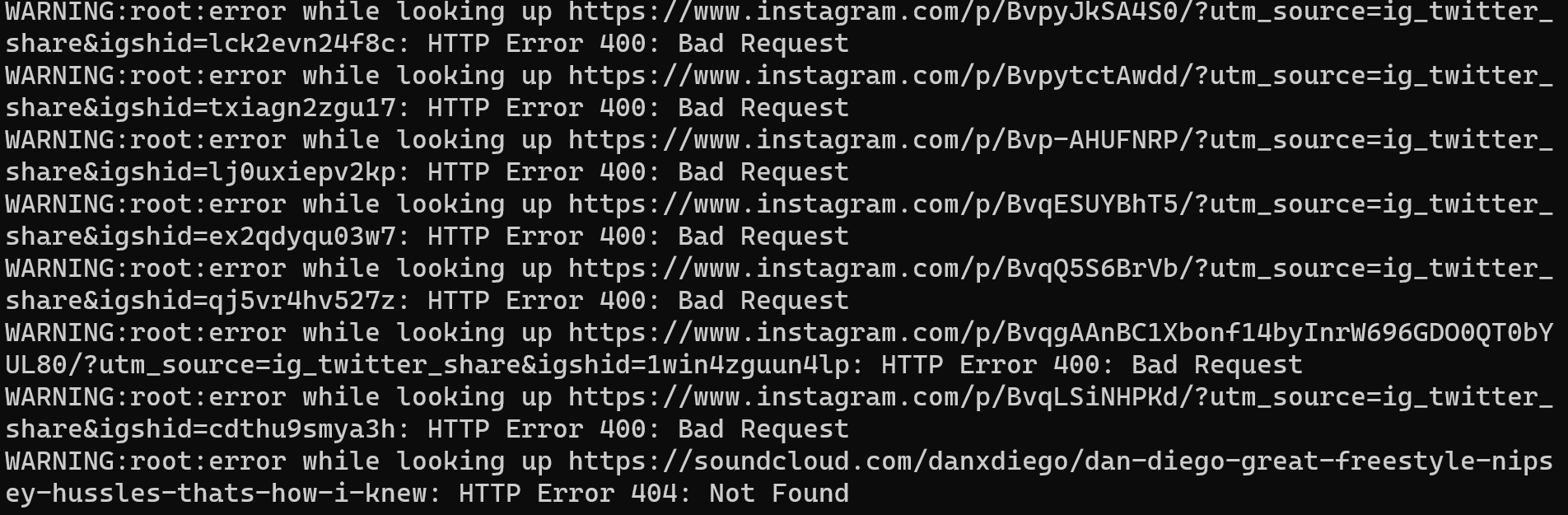
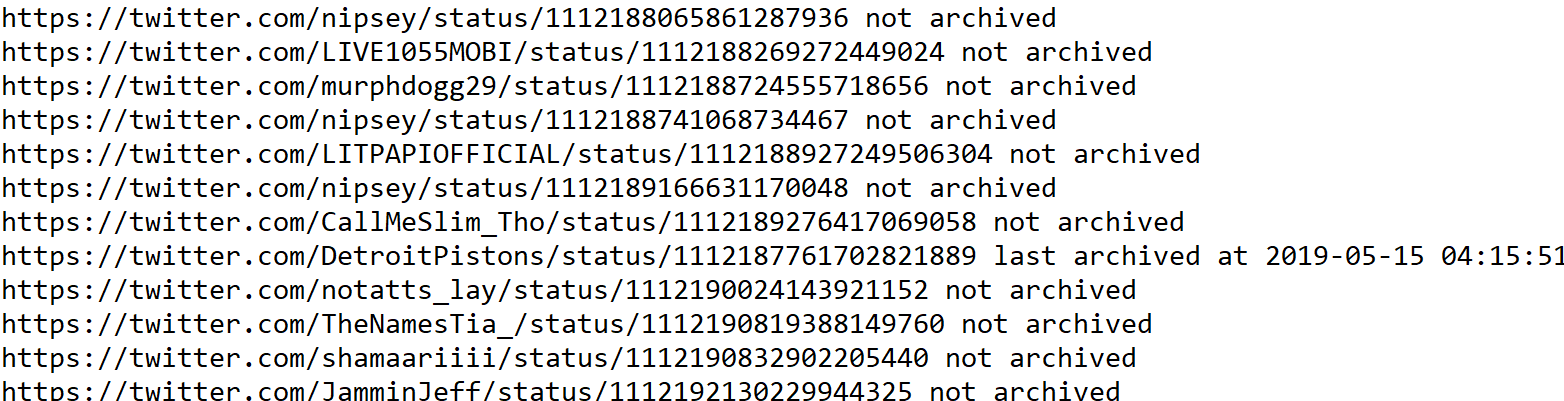
Note: Warning messages like the following will be printed to the command line if the url has been deleted.
tweet.py
We’ll use one of the first tweet id in our dataset.
python utils/tweet.py 1112143431197835264 > nh_dod_tweet.jsonl
tweet_compliance.py
python utils/tweet_compliance.py nh_dod_ids.txt > nh_dod.jsonl > nh_dod_tweet_compliance.jsonl
The current tweets will be output to a dod_tweet_compliance.jsonl.
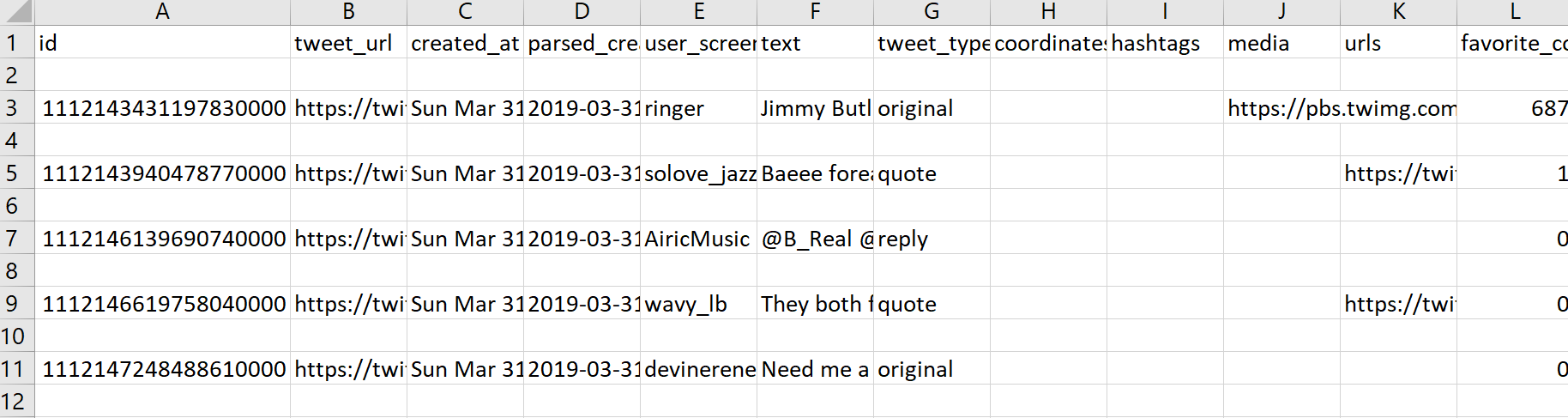
The ids of tweets that are not available are output to the command line along with the deleted tweets.

wayback.py
python utils/wayback.py nh_dod.jsonl > nh_dod_wayback.txt
Organizing the Data
sort_by_id.py
This one is pretty simple. It just sorts the dataset in ascending order by id. It’s essentially the same as sorting by date as tweet ids are parsed out in order of creation.
python utils/sort_by_id.py nh_dod.jsonl > nh_dod_sort_by_id.jsonl
unshrtn.py
We want to be able to print out the unshortened urls in the dataset. To do so, we must first use unshrtn.py to fully expand the urls, and then urls.py to print them out.
python utils/unshrtn.py nh_dod.jsonl > nh_dod_unshrtn.jsonl
urls.py
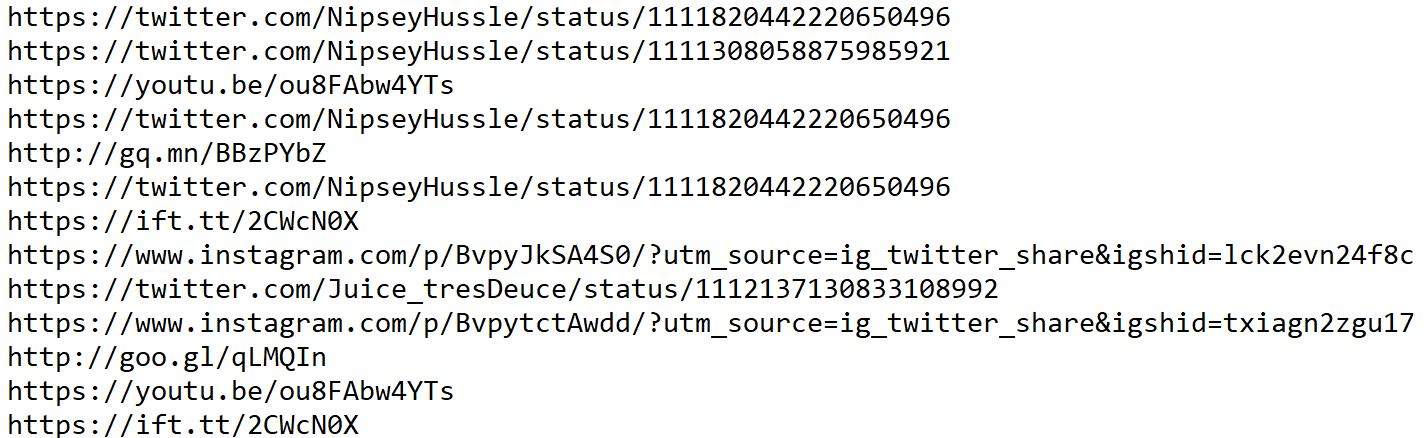
python utils/urls.py dod_unshrtn.jsonl > nh_dod_urls.txt
This is the output from using unshrtn.py before running urls.py.
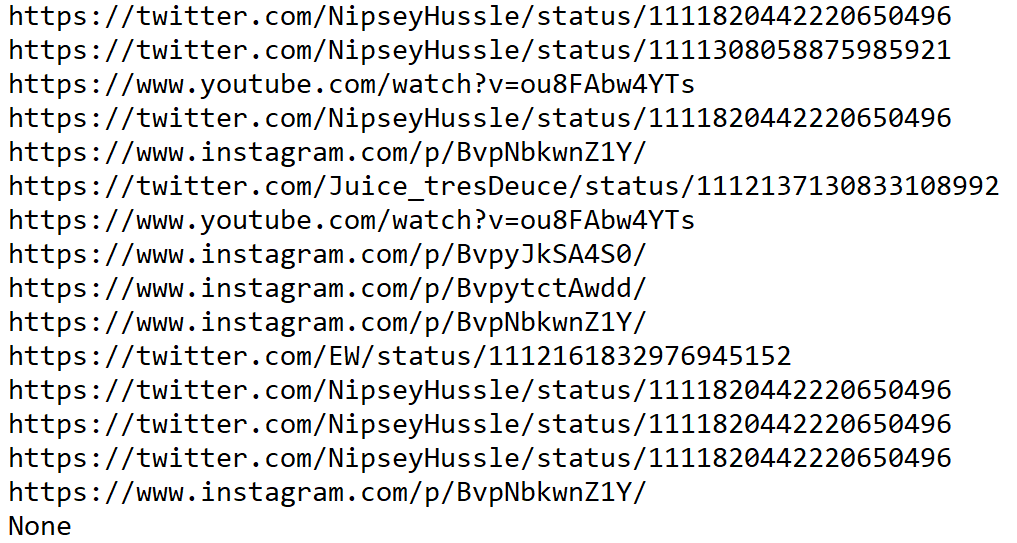
We can compare this with the ouput from running urls.py without using unshrtn.py first.
youtubedl.py
This utility downloads youtube content and places it in a directory youtubedl.
python utils/youtubedl.py nh_dod.jsonl > nh_dod_youtubedl.jsonl